
URL's, Paths, Absolute and Relative Addresses
Part 1: URLs
URL stands for Uniform Resource Locator. What it means is that it's a specific address that is needed to locate a specific file at a Web site.
Whenever you're looking at a web page, you are actually looking at a specific file, or files, in a specific location on a specific drive somewhere. Consequently, all URLs need to be unique.
The first three parts of a full URL pertain to the domain names and server name from right to left respectively.
Example.: www.ucla.edu
Starting from the right side, all URLs contain a TLD (top level domain). In this case it's ".edu". Other TLDs are .com. .gov, .net, etc. There are also two letter TLDs for countries. Note that .tv represents a country in the South Pacific.
The TLD is preceded on the left by a what is technically a sub domain (ucla), but commonly referred to simply as the domain name.
Finally, we have the name of the server, which is conventionally named, simply, "www". However, many servers have other names, hence not all full URL addresses start with "www".
The "http://" that is needed in front of a full URL in order for it to work refers to the transfer protocol. "http" represents the hypertext transfer protocol which is used for sending web pages. Another transfer protocol that you may have heard of is ftp (file transfer protocol).
The transfer protocol is not to be confused with the URL. They are different things. The URL specifies the location of the file. The transfer protocol specifies the manner in which the file will be sent. We will discuss web protocols later.
Now let's look at the rest of the URL. If there is any additional information to the right of the TLD it is going to be the "path" to the file on the server. For example, in the following URL the path starts with: /extension ...and ends with the file name: index.html.
www.ucla.edu/extension/infosystems/webtech/index.html
Hopefully you are somewhat familiar with what is meant by a "path" in computer jargon. It means the trail to the file. It is represented by the names of the directories (also called folders) that enclose the file, starting with the largest one and working all the way down to the file name itself. (Please note that a directory is the UNIX and DOS equivalent of a folder in Windows or Mac - they are the same thing, just different words.)
UNIX syntax is used in URLs. Each forward slash (/) that you see in a web address represents a directory (folder).
A path is similar to those Russian wooden dolls: when you open the outer one you find another doll inside of it. And when you open that doll, there's yet another, etc., etc., until you finally get to the smallest one, which would be analogous to the web page you want to see.

Part 2: Paths
To get a better idea of what we're talking about, look at this
graphic representation of a Web site hierarchy.
Here you'll see that a Web site file structure consists of a hierarchy of folders within folders and files within those folders. Sometimes files are on the same "tier" or level as a folder.
Now that you know a bit about what a URL's path is, let's talk about how Web pages at a given site refer to one another in the html code.
For example, if you have a Web page with a link to another page at your site, how does it know where to find the other page in order to open it? The answer is that the HTML code contains the path, also called the URL to the other page.
When a link is to another page within the same site, it is usually coded as what’s called a relative address. A relative address includes just enough information for the link to find what it's looking for at the local site.
When you are creating Web pages you will probably want to use these relative URLs to the other pages within your site. This is because they allow the file that is being specified to be located faster, among other things.
During this part of the lesson you should use Windows Explorer (not to be confused with Internet Explorer) to familiarize yourself with paths and directory (folder) structures on your computer.
You can launch Windows Explorer by right-clicking on the Start button in the lower left corner of your screen and selecting Explore. Mac users, use the Column view in the Finder.
More About Paths: An Analogy
Paths are simply the directions for how to get to the location of where a file is stored. They're a lot like the directions one might have for how to send a letter to an individual in an office. For example, here are the items you might include in a mailing address, the final destination is listed at top:
Mr. Joe File
Office 19
Floor 32
100 Fifth Avenue
Los Angeles
California
The directions to a file that are contained in a URL are similar to this. They are listed after a forward slash (/) to the right of the TLD. They then proceed from left to right. The first forward slash to the right of the TLD represents the root directory of the site.
As you proceed through the path's address from left to right you are going from the broadest part of the address to the most specific; from the largest to smallest hierarchical level. Each level of directories in a URL is separated by a forward slash.
Just for fun, I have modified the above mailing address to look something like a file path. This is what the URL to Joe would be if Joe were file:
www.domainname.com/california/losangeles/100_fifth_ave/floor32/office19/joe.html
NOTE: You should not use spaces or any characters other than numbers and letters in your folder and file names. If you need to represent a space, use an under_score.
On the web server that the Joe "file" is a file on, the path would look like this (in UNIX syntax):
/california/losangeles/100fifthavenue/floor32/office19/joefile.html
What you see are the relationships of the files to one another and to the site root directory. If the server used Windows, the following is an illustration of what the path to Joe might look like as seen in Windows Explorer:
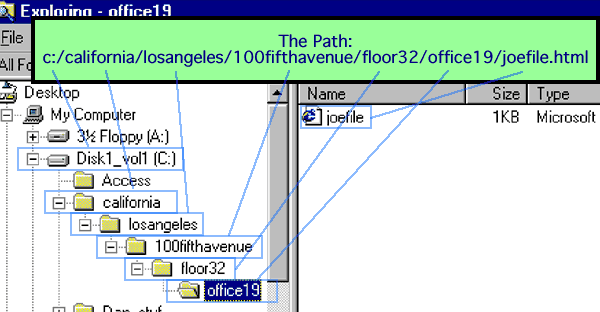
 Absolute
and Relative Addresses
Absolute
and Relative Addresses
What are these? Using the analogy of Joe's office address again: if you were in an office in the same building as Joe, but two floors down on 30th floor, and someone asked you where Joe's office was, you'd probably say something like this:
"He's two floors up, in the first office on the left" - or - "He's on the 32nd floor, in office 19"
In both cases you would be using a relative address, meaning that you are providing an address that is in relationship to where you are. This is a lot easier to say, to understand, and to remember than including the street address, city, and state. If the directions include all of those specifics, it would be called an absolute address.
When you are provided all the details necessary to find Joe no matter where you are, you would be using an absolute address. This is the same as a complete mailing address, such as the one we saw in the prior section, More About Paths.
In the same manner that a full mailing address will get a letter delivered no matter where it is mailed from, an absolute address will get you to the file you want regardless of where your code is located.
When creating links to other files within your Web site, it's usually preferable to use relative addresses for these reasons:
- There's less code, so the file containing the code with the link in it downloads faster.
- The files take less time to be located and sent to the browser because the search for them is limited to a nearby folder.
- It's often easier to modify the paths if they change.
- It often allows one to move groups of files around within a site with minimal risk of "breaking" a path.
Relative Addresses: The dots and backslashes tell you where to look:
There are special rules for writing relative links. UNIX syntax is used. When referring to the location of other files at the same site, the following syntax is used:
../ means go "up" one folder level (to the next larger folder) and
then you will find the file or folder you're looking for.
../../ means to go up two folder levels to find it.
../../../ goes up three folders then looks for it
For example:
../../../images/photo.jpg
…means: go up beyond the current folder, one, two, three folder levels,
…then look for the folder called "images" inside of which you
should find the file "photo.jpg"..
To include the image on a Web page, the code might look like this example of a relative address:
<img src="../../../images/photo.jpg">
Document Relative and Site Root Relative Paths
Now to complicate things somewhat, there are two types of relative addresses: document relative and site root relative. We have been discussing document relative paths. A site route relative path is half way between an absolute and a document relative path.
A site root relative path is relative the root folder. This is the folder on the server that contains the site. This is represented by a forward slash in front of the address. An example of this would be the following:
<img src="/hotels/east/nyc/images/photo.jpg">
This is the equivalent of saying, "Start at the top folder level that our site files are kept in, look for a folder called hotels, then inside of that folder look for a folder called east. Inside of east look for a folder called nyc. Inside of that look for a folder called images inside of which you should see the file photo.jpg
The advantage of a site root relative path is that it can be used anywhere within a site. This is particularly useful with the code for navigation buttons. As long as the path will work anywhere in the site, then it can be put anywhere within the site and still work properly.
About absolute addresses:
These contain complete URL's including the transfer protocol. There's nothing fancy about an absolute URL. It works anywhere as long as the page it is pointing to has not moved. Here's an example of an absolute address:
<img src="http://www.gis.net/hotels/east/nyc/images/photo.jpg">
If the link you have is going to a page that's not on your own server, then it must use an absolute URL.
The Home Page's File Name is Usually index.html
You have probably noticed that a file name is not usually needed when you want to go to a home page. The reason it isn't is because servers look for a file called index.html when no file name is provided.
For this reason most home page files are named index.html (or .htm). Because of this, people only need to remember the domain name, and not a specific file name.
If you enter the url http://www.ucla.edu, a page will be sent to you. The file name of the page is usually index.html. Fortunately you don't need to remember the file name. You only need to remember "ucla" and "edu".
